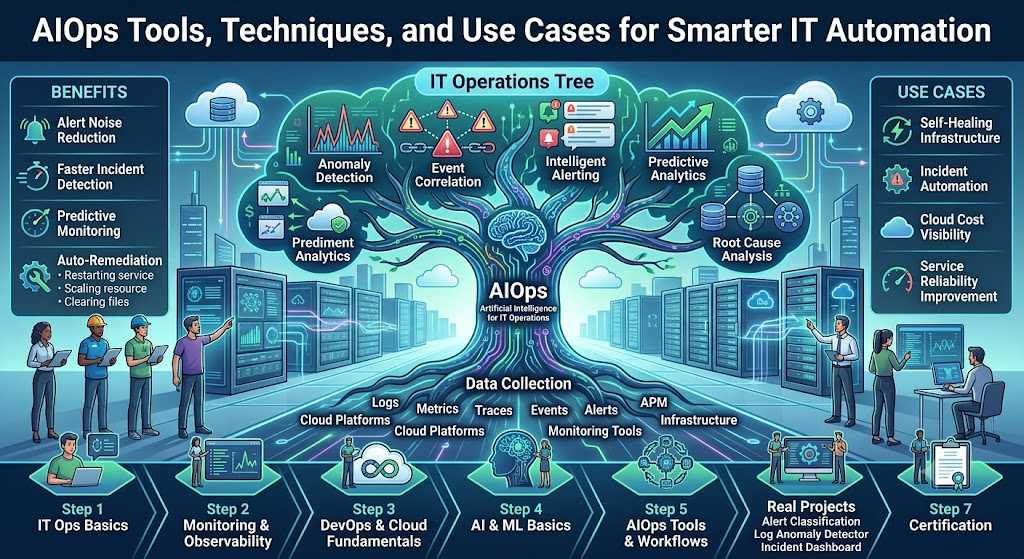
Introduction
Modern IT operations are becoming more complex every day. A few years ago, IT teams mostly managed servers, applications, networks, databases, and basic monitoring dashboards. Today, the same teams handle cloud platforms, microservices, containers, APIs, security alerts, logs, metrics, traces, automation workflows, and business-critical digital services.
Because of this complexity, traditional monitoring is no longer enough. IT teams often receive thousands of alerts from different tools. Some alerts are useful, while many are duplicate, noisy, or low priority. Engineers spend too much time checking dashboards, reading logs, identifying root causes, and manually fixing repeated incidents.
This is where AIOps becomes important.
AIOps helps IT teams use artificial intelligence, machine learning, automation, and observability data to manage modern systems more intelligently. It supports faster incident detection, better root cause analysis, intelligent alerting, predictive monitoring, and auto-remediation.
For DevOps engineers, SREs, cloud engineers, monitoring teams, automation engineers, freshers, and IT managers, AIOps is becoming a future-ready skill. It connects IT operations with AI-driven decision-making and helps organizations build more reliable, automated, and scalable systems.
What is AIOps?
AIOps means Artificial Intelligence for IT Operations. In simple words, AIOps uses AI, machine learning, data analytics, monitoring, and automation to improve IT operations.
Traditional IT operations depend heavily on human teams. Engineers monitor systems, check alerts, analyze logs, find problems, and fix issues manually. AIOps improves this process by helping teams understand large volumes of operational data faster.
AIOps collects data from different sources such as:
- Logs
- Metrics
- Events
- Traces
- Alerts
- Cloud platforms
- Monitoring tools
- Application performance tools
- Infrastructure systems
After collecting this data, AIOps tools analyze patterns, detect unusual behavior, connect related events, reduce alert noise, and suggest possible actions. In advanced environments, AIOps can also trigger automation workflows to fix known issues automatically.
For example, if an application suddenly becomes slow, AIOps can analyze logs, metrics, recent deployments, infrastructure health, and user impact. It can help identify whether the issue is caused by high CPU usage, database latency, memory leaks, network delay, or a failed service dependency.
So, AIOps is not only about AI. It is a combination of AI, monitoring, observability, automation, DevOps practices, and IT operations knowledge.
Why AIOps Matters for Modern IT Teams
AIOps matters because modern IT systems are too large and fast-changing to manage only through manual processes. Cloud-native applications, distributed systems, and DevOps pipelines create huge amounts of data. Without intelligent automation, teams can miss important signals or spend too much time on repeated tasks.
Alert Noise Reduction
One of the biggest problems in IT operations is alert noise. Teams may receive hundreds or thousands of alerts in a day. Many alerts may come from the same root issue.
AIOps helps group related alerts together. It can identify duplicate alerts, suppress low-value notifications, and highlight the alerts that need immediate attention. This helps engineers focus on real problems instead of wasting time on noise.
Faster Incident Detection
In traditional monitoring, teams often detect incidents after users complain or after dashboards show visible failures. AIOps improves this by identifying early warning signs.
It can detect unusual patterns in application response time, error rates, traffic, infrastructure usage, or logs. This helps teams respond before small issues become major outages.
Root Cause Analysis
Finding the real cause of an incident can take a long time. Engineers may need to check logs, metrics, traces, recent changes, cloud resources, and deployment history.
AIOps supports root cause analysis by connecting different signals. It can show which service, server, database, network component, or recent change is most likely responsible for the issue.
Predictive Monitoring
AIOps can also support predictive monitoring. Instead of only reacting after a problem happens, teams can predict possible issues.
For example, AIOps can help identify when disk space may run out, when traffic may exceed capacity, or when system performance may degrade based on past trends.
Auto-Remediation
Auto-remediation means fixing known issues automatically using predefined automation workflows.
For example:
- Restarting a failed service
- Scaling cloud resources
- Clearing temporary files
- Rolling back a failed deployment
- Opening an incident ticket
- Notifying the right team
AIOps can trigger these actions when it identifies a known issue pattern. This reduces manual effort and improves response time.
Better Reliability
The final goal of AIOps is better reliability. When teams detect problems faster, reduce noise, automate repeated fixes, and understand root causes clearly, systems become more stable.
This is especially useful for SRE teams, DevOps teams, cloud operations teams, and platform engineering teams.
AIOps vs MLOps
AIOps and MLOps are related to AI and machine learning, but they are not the same.
AIOps focuses on improving IT operations using AI and automation. MLOps focuses on managing the lifecycle of machine learning models.
| Area | AIOps | MLOps |
|---|---|---|
| Main Focus | IT operations and automation | Machine learning model lifecycle |
| Primary Users | DevOps engineers, SREs, IT operations teams, cloud teams | Data scientists, ML engineers, data engineers |
| Main Goal | Improve monitoring, incidents, alerts, reliability, and automation | Build, deploy, monitor, and manage ML models |
| Common Data | Logs, metrics, traces, alerts, events | Training data, model data, features, predictions |
| Key Activities | Anomaly detection, alert correlation, root cause analysis, auto-remediation | Model training, model deployment, model monitoring, versioning |
| Business Value | More reliable IT systems and faster incident response | Better ML model delivery and production performance |
AIOps and MLOps can also work together. For example, MLOps practices can help build and manage the machine learning models used inside AIOps platforms. At the same time, AIOps can help monitor the infrastructure where ML models are running.
This is why many professionals are now interested in both AIOps and MLOps. Learning both areas can improve career opportunities in modern IT, cloud, automation, and AI-driven operations.
Core Skills Needed to Learn AIOps
AIOps is a practical field. To learn it properly, beginners should build strong foundations instead of directly jumping into tools.
Monitoring and Observability
Monitoring helps teams check whether systems are working. Observability goes deeper. It helps teams understand why a system is behaving in a certain way.
To learn AIOps, you should understand:
- Metrics
- Logs
- Traces
- Events
- Dashboards
- Alerts
- Service health
- System behavior
Observability is one of the most important foundations of AIOps.
Log Analysis
Logs contain important information about application behavior, errors, user activity, system events, and failures. AIOps tools often use log data to detect patterns and anomalies.
Beginners should learn how to read logs, search logs, filter errors, and identify repeated patterns.
Metrics and Traces
Metrics show numerical data such as CPU usage, memory usage, request count, response time, error rate, and database latency.
Traces help track how a request moves across different services in a distributed system.
Both metrics and traces are important for understanding performance and reliability.
Incident Management
AIOps is closely connected with incident management. You should understand how incidents are detected, assigned, investigated, resolved, and reviewed.
Important concepts include:
- Incident priority
- Escalation
- On-call process
- Root cause analysis
- Post-incident review
- Service level objectives
Cloud Basics
Modern AIOps is often used in cloud environments. Basic knowledge of cloud platforms, virtual machines, containers, storage, networking, and scaling is useful.
You do not need to be a cloud expert in the beginning, but you should understand how cloud infrastructure works.
Python Basics
Python is useful for automation, data analysis, log processing, API integration, and machine learning basics. Many AIOps workflows can be improved using Python scripts.
Beginners should learn:
- Variables
- Loops
- Functions
- File handling
- APIs
- Basic data analysis
- Automation scripts
Machine Learning Fundamentals
AIOps uses machine learning for anomaly detection, prediction, classification, clustering, and pattern recognition.
You do not need advanced mathematics at the start. However, you should understand basic ML concepts such as:
- Training data
- Models
- Features
- Predictions
- Classification
- Clustering
- Anomaly detection
DevOps and Automation
AIOps supports DevOps automation. So, DevOps knowledge is very helpful.
You should understand:
- CI/CD pipelines
- Infrastructure as Code
- Configuration management
- Containers
- Deployment automation
- Monitoring in DevOps
- Incident response workflows
Popular AIOps Use Cases
AIOps can be used in many practical IT operations scenarios. Below are some of the most common use cases.
Anomaly Detection
Anomaly detection means identifying unusual behavior in systems.
For example, if an application normally has a 1% error rate but suddenly reaches 10%, AIOps can detect this change. Similarly, if CPU usage, memory usage, traffic, or response time suddenly changes, AIOps can highlight it.
This helps teams detect problems early.
Event Correlation
In large IT environments, one issue can generate many alerts. Event correlation helps connect related events and identify the main problem.
For example, if a database goes down, multiple applications may show errors. Instead of treating every application alert separately, AIOps can correlate them and show that the database failure is the likely root cause.
Intelligent Alerting
Traditional alerting often creates too many notifications. Intelligent alerting improves this by ranking alerts based on impact, urgency, and context.
AIOps can help decide which alerts matter most and which alerts can be grouped, delayed, or ignored.
Capacity Prediction
AIOps can study historical usage patterns and predict future capacity needs.
For example, it can help answer questions like:
- Will storage run out soon?
- Will traffic exceed current infrastructure limits?
- Is cloud resource usage increasing?
- Do we need to scale before a business event?
This helps teams plan better and avoid last-minute problems.
Self-Healing Infrastructure
Self-healing infrastructure means systems can detect known issues and fix them automatically.
For example:
- Restarting failed containers
- Scaling resources during high traffic
- Replacing unhealthy instances
- Clearing cache
- Triggering backup workflows
AIOps makes self-healing more intelligent by connecting monitoring with automation.
Incident Automation
AIOps can automate repeated incident response steps.
For example, when a known alert appears, AIOps can automatically:
- Create an incident ticket
- Attach logs and metrics
- Assign the issue to the right team
- Run diagnostic scripts
- Suggest possible root causes
- Trigger approved remediation steps
This saves time and improves response quality.
Cloud Cost Visibility
Cloud environments can become expensive if resources are not monitored properly. AIOps can help detect unusual usage patterns, unused resources, over-provisioned systems, and cost spikes.
This helps cloud teams improve both performance and cost control.
Service Reliability Improvement
AIOps supports service reliability by helping teams understand system behavior, detect risks early, and improve incident response.
For SRE teams, AIOps can support service level objectives, error budget analysis, incident trends, and reliability improvements.
AIOps Tools and Techniques
AIOps tools usually combine monitoring, data analysis, machine learning, automation, and incident management features. Different tools may focus on different areas, such as observability, alert correlation, log analytics, incident response, or automation.
Common AIOps techniques include:
- Data collection from multiple systems
- Log and metric analysis
- Anomaly detection
- Event correlation
- Noise reduction
- Pattern recognition
- Predictive analytics
- Root cause analysis
- Automated remediation
- Incident workflow automation
When choosing AIOps tools, teams should first understand their operational problems. A tool is useful only when it solves a real problem.
For example, if your team struggles with too many alerts, focus on alert correlation and noise reduction. If your team struggles with repeated manual fixes, focus on automation and auto-remediation. If your team struggles with system visibility, focus on observability and monitoring.
AIOps tools should support your process. They should not replace basic engineering discipline.
AIOps Learning Roadmap for Beginners
Learning AIOps becomes easier when you follow a clear roadmap.
Step 1: Learn IT Operations Basics
Start with the basics of IT operations. Understand how applications, servers, databases, networks, and cloud systems work.
Learn what happens when a system fails and how teams investigate issues.
Step 2: Understand Monitoring and Observability
Next, learn monitoring and observability. Understand metrics, logs, traces, dashboards, alerts, and service health.
Practice reading monitoring dashboards and identifying system behavior.
Step 3: Learn DevOps and Cloud Fundamentals
AIOps is closely connected with DevOps and cloud operations. Learn the basics of CI/CD, containers, cloud infrastructure, automation, and deployment workflows.
This will help you understand where AIOps fits in real projects.
Step 4: Learn AI and ML Basics
After that, learn basic AI and machine learning concepts. Focus on practical ideas like anomaly detection, classification, clustering, and prediction.
You do not need to become a data scientist, but you should understand how ML helps IT operations.
Step 5: Practice AIOps Tools and Workflows
Start practicing with AIOps tools, monitoring tools, log analysis tools, and automation workflows.
Try to connect data sources and understand how alerts, logs, metrics, and incidents work together.
Step 6: Work on Real Projects
Real learning happens through projects. Build small projects that solve actual IT operations problems.
For example, create a log anomaly detector, alert classification system, or auto-remediation workflow.
Step 7: Prepare for AIOps Certification
After gaining practical knowledge, you can prepare for an AIOps certification. Certification can help structure your learning and validate your understanding.
A good AIOps training path should include concepts, tools, use cases, hands-on labs, projects, and real-world incident scenarios.
Real-World AIOps Project Ideas
Projects are very important for building confidence. Here are some practical project ideas for beginners and working professionals.
Alert Classification System
Create a system that classifies alerts into categories such as critical, warning, duplicate, informational, or false positive.
This project helps you understand alert management and intelligent alerting.
Log Anomaly Detector
Build a simple log anomaly detection system that identifies unusual error patterns from application logs.
This project helps you learn log analysis, pattern detection, and machine learning basics.
Incident Prediction Dashboard
Create a dashboard that uses historical metrics to predict possible incidents.
For example, you can track CPU usage, memory usage, request failures, and latency trends.
Auto-Remediation Workflow
Build an automation workflow that restarts a failed service or sends an alert when a known issue appears.
This project helps you understand the connection between monitoring and automation.
Cloud Monitoring Pipeline
Create a pipeline that collects cloud infrastructure metrics, stores them, and displays them in a dashboard.
This helps you learn cloud monitoring, observability, and capacity planning.
Who Should Learn AIOps?
AIOps is useful for many roles in modern IT.
DevOps Engineers
DevOps engineers can use AIOps to improve CI/CD monitoring, deployment reliability, infrastructure automation, and incident response.
SREs
SREs can use AIOps for service reliability, error budget analysis, incident automation, and root cause analysis.
Cloud Engineers
Cloud engineers can use AIOps for cloud monitoring, capacity planning, cost visibility, and infrastructure automation.
IT Operations Teams
IT operations teams can use AIOps to reduce alert noise, improve incident response, and manage complex systems more efficiently.
Monitoring Engineers
Monitoring engineers can use AIOps to build better dashboards, alert rules, event correlation, and observability workflows.
Managers
Managers can use AIOps knowledge to understand operational risk, team productivity, reliability improvement, and automation strategy.
Freshers
Freshers who want a modern IT career can learn AIOps to build skills in monitoring, DevOps automation, cloud, AI-driven IT operations, and MLOps basics.
Common Mistakes Beginners Make
Beginners often make some common mistakes while learning AIOps.
Learning Tools Without Concepts
Many beginners directly start with tools. This is not the best approach. Tools are important, but concepts are more important.
First, understand monitoring, observability, incidents, logs, metrics, and automation. Then learn tools.
Ignoring Observability Basics
AIOps depends on good observability data. If logs, metrics, and traces are poor, AIOps results will also be weak.
Strong observability is the foundation of successful AIOps.
Depending Only on AI Without Human Review
AI can support decisions, but human review is still important. AIOps should help engineers, not blindly replace them.
Teams should review recommendations, validate patterns, and control automation carefully.
Not Practicing Real Incidents
AIOps is practical. Reading theory is not enough. Beginners should study real incident scenarios, failure patterns, and root cause analysis examples.
Skipping Automation Fundamentals
Auto-remediation needs automation skills. Without basic scripting, DevOps, and workflow automation knowledge, it becomes difficult to implement AIOps properly.
AIOps Career Opportunities
AIOps can open many career opportunities in modern IT operations.
AIOps Engineer
An AIOps Engineer works on AI-driven IT operations, monitoring automation, alert correlation, incident analysis, and remediation workflows.
MLOps Engineer
An MLOps Engineer focuses on machine learning model deployment, monitoring, automation, and production ML systems. AIOps and MLOps skills can complement each other.
SRE
A Site Reliability Engineer uses automation, observability, and reliability practices to keep systems stable and scalable. AIOps can improve SRE workflows.
Platform Engineer
Platform engineers build internal platforms for developers and operations teams. AIOps can help make platforms more reliable and intelligent.
Cloud Automation Engineer
Cloud automation engineers work on cloud infrastructure, automation scripts, scaling, monitoring, and cost optimization. AIOps adds intelligence to these workflows.
Observability Engineer
Observability engineers focus on logs, metrics, traces, dashboards, and system visibility. AIOps helps them move from basic monitoring to intelligent operations.
AIOps Training and Certification Value
AIOps training helps learners understand the complete process of AI-driven IT operations. A good training program should cover both theory and practical use cases.
Useful AIOps training should include:
- Monitoring and observability basics
- AIOps concepts
- Log analysis
- Metrics and traces
- Anomaly detection
- Alert correlation
- Automation workflows
- Incident management
- Real-world projects
- Certification preparation
An AIOps certification can help professionals show that they understand modern IT operations, AI-driven automation, and practical AIOps use cases. However, certification should be supported by hands-on practice.
The best learning approach is simple: learn concepts, practice tools, build projects, understand real incidents, and then prepare for certification.
FAQs
1. What is AIOps in simple words?
AIOps means using artificial intelligence, machine learning, monitoring, and automation to improve IT operations. It helps teams detect problems faster, reduce alert noise, find root causes, and automate repeated tasks.
2. Why is AIOps important for IT teams?
AIOps is important because modern IT systems generate huge amounts of data. It helps teams manage alerts, logs, metrics, incidents, and automation more intelligently.
3. Is AIOps only for large companies?
No. AIOps is useful for both large and growing organizations. Any team managing complex applications, cloud systems, alerts, and incidents can benefit from AIOps practices.
4. What skills are required to learn AIOps?
Important skills include monitoring, observability, log analysis, metrics, traces, incident management, cloud basics, Python basics, machine learning fundamentals, DevOps, and automation.
5. What is the difference between AIOps and MLOps?
AIOps focuses on IT operations, monitoring, alerts, incidents, and automation. MLOps focuses on building, deploying, monitoring, and managing machine learning models in production.
6. Can freshers learn AIOps?
Yes. Freshers can learn AIOps by starting with IT operations basics, monitoring, cloud fundamentals, DevOps, Python, and basic machine learning concepts.
7. What are common AIOps use cases?
Common AIOps use cases include anomaly detection, event correlation, intelligent alerting, root cause analysis, capacity prediction, auto-remediation, incident automation, and cloud cost visibility.
8. Does AIOps replace DevOps engineers or SREs?
No. AIOps supports DevOps engineers and SREs. It helps them work faster and smarter, but human judgment, engineering knowledge, and decision-making are still important.
9. Is AIOps certification useful?
AIOps certification can be useful when it includes practical learning, real-world projects, and strong concepts. It can help professionals structure their learning and show their skills.
10. How should I start learning AIOps?
Start with IT operations, monitoring, observability, DevOps, cloud basics, Python, and machine learning fundamentals. Then practice AIOps tools, build projects, and prepare for certification.
Conclusion
AIOps is becoming an important skill for modern IT professionals because IT systems are growing more complex, dynamic, and data-heavy. Traditional monitoring alone cannot handle the speed and scale of today’s cloud, DevOps, and distributed environments.
With AIOps, teams can reduce alert noise, detect incidents faster, improve root cause analysis, predict problems, automate repeated fixes, and build more reliable systems.
For DevOps engineers, SREs, cloud engineers, monitoring engineers, automation professionals, managers, and freshers, AIOps offers a strong career path. It connects IT operations with AI, machine learning, observability, automation, and reliability engineering.
The best way to learn AIOps is to build strong foundations, practice real workflows, understand incidents, work on projects, and then prepare for AIOps certification. When learned properly, AIOps can help professionals become future-ready in the world of AI-driven IT operations.